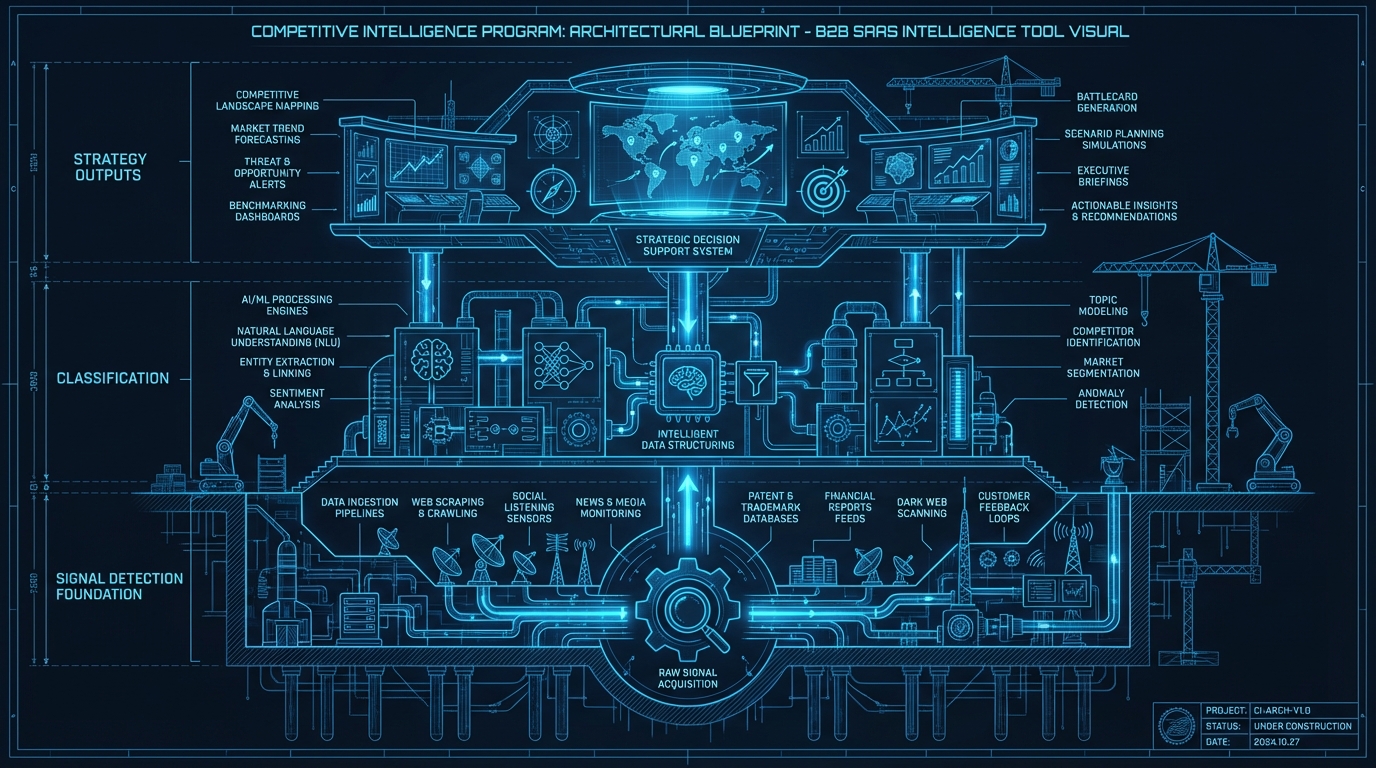
Most CI programs start with a deliverable. A PMM gets asked for a battlecard. They build one. Someone likes it. They build three more. Six months later, there is a folder of battlecards that may or may not be current, a Slack channel where people occasionally share competitor screenshots, and a vague sense that the team should be doing more. That is not a CI program. That is a CI artifact collection. A CI program has a defined detection layer, a classification system, a distribution mechanism, and an activation loop. This guide walks through building each layer deliberately, starting from the bottom. The order matters more than most guides admit.
QUICK ANSWER
A competitive intelligence program requires four layers: detection (verified signal capture), classification (what type of move is this), distribution (getting intelligence to the right people), and activation (turning intelligence into action). Most programs fail because they skip the detection layer and build deliverables on top of unverified intelligence. Building detection first produces a program that is defensible, scalable, and actually changes deal outcomes.
> **Quick Answer:** A competitive intelligence program is built in four layers: detection, classification, distribution, and activation. The most common failure mode is building deliverables (battlecards, newsletters) before establishing a reliable, verified detection layer. Programs that start with evidence-backed signal capture produce more defensible intelligence, require less maintenance, and produce better win rates on competitive deals.
—
## Why Most CI Programs Are Built Backwards
Ask any PMM what their CI program produces and they will list deliverables: battlecards, competitive newsletters, SWOT analyses, positioning briefs. Ask them where the information in those deliverables comes from and the answer gets murkier. Manual website checks. Listening to sales calls. A quarterly sweep of the competitor blog. RSS feeds that someone set up in 2023 and no longer reads.
The deliverable layer is visible. It is what leadership asks for. So teams build it first, then try to fill it with intelligence, and end up filling it with whatever is findable rather than whatever is accurate.
The result is a CI program that produces content on a schedule rather than a program that produces intelligence on demand. The distinction sounds subtle. In a competitive deal, it is everything.
—
## The 4-Layer CI Program Architecture
### Layer 1: Detection
Detection is the foundation. Everything else sits on top of it.
Detection answers one question: when a competitor makes a move on a web property we care about, how quickly do we know about it, and how do we know it is real?
A detection system covers:
– Which competitor pages are being monitored (homepage, pricing, features, blog, changelog, careers, newsroom)
– At what frequency (pricing pages warrant hourly monitoring; blog pages warrant daily)
– What change threshold triggers an alert (minor text formatting versus substantive content changes)
– Whether alerts include evidence (before/after page state) or just a notification
Most teams start with Google Alerts and quickly discover the problem: alerts are noisy, they fire on news articles about competitors rather than changes to competitor pages, and they produce no before/after evidence. The result is a detection layer that requires manual verification of every alert, which eliminates most of the time savings.
A production-grade detection layer captures the actual page state, compares it to a baseline, and surfaces only changes that exceed a meaningful threshold. That is a crawl-and-diff system, not an alert subscription.
**What to build or buy:** For teams at pre-Series B scale, building a crawl-and-diff system in-house is rarely the right call. The engineering cost is real: crawler infrastructure, extraction rules, baseline management, diff algorithms, false-positive suppression. A purpose-built CI tool that handles this layer is usually more cost-effective. Metrivant’s detection layer covers 795 pages at crawl cadences ranging from 30 minutes for high-value pages to daily for ambient content.
### Layer 2: Classification
Classification answers: what type of move is this, and how significant is it?
Raw page diffs are not intelligence. A pricing page change could be a cosmetic update to the button color or a full tier restructure. A homepage change could be a seasonal image swap or a strategic repositioning. Classification is what separates a signal from noise.
A useful classification system distinguishes between:
– Feature launches vs. minor UI updates
– Pricing restructures vs. promotional pricing changes
– Positioning shifts (messaging, target audience, brand language)
– Market expansion signals (new vertical pages, new geo pages)
– Hiring signals (job listings indicating investment in specific areas)
– Momentum signals (review count changes on G2/Capterra, press coverage)
Classification can be done manually by a CI analyst, algorithmically by a machine learning layer, or through a deterministic pipeline that applies rules to extracted content. The key is consistency: the same type of change should produce the same classification every time, with a confidence score that reflects how certain the system is.
Metrivant’s classification layer uses a deterministic pipeline (not generative AI) to classify changes into types including feature_launch, pricing_change, positioning_shift, market_expansion, and product_expansion. Each signal comes with a confidence score and a strategic implication built on the before/after evidence.
### Layer 3: Distribution
Distribution answers: who needs to know about this, and how do they receive it?
A detected, classified signal that sits in a dashboard no one checks is not useful intelligence. Distribution is what turns detection into action at the right moment.
Distribution channels for CI programs:
– Slack or Teams alerts for high-priority signals (pricing changes, major feature launches)
– Email digest for weekly competitive updates
– CRM integration for deal-specific competitive intelligence (surfacing relevant signals when a deal enters a competitive stage)
– Battlecard updates triggered by verified signals
– Sales rep notifications before competitive calls
Distribution design requires two decisions: what gets pushed vs. pulled, and who is in the distribution path. Not every signal needs to reach every salesperson. A pricing change on a competitor’s enterprise tier is relevant to enterprise reps and sales leadership. It is noise for an SMB rep working a different segment. Segmenting the distribution path by role and deal type keeps signals actionable rather than overwhelming.
### Layer 4: Activation
Activation answers: what action did the intelligence produce?
This is the layer most CI programs never formally build, which is why “pipeline influenced” metrics are hard to calculate. If you track only that a signal was detected and distributed, you have no way of knowing whether anyone acted on it.
Activation tracking looks like:
– A battlecard was updated within 24 hours of a competitor pricing change
– A sales rep received and read a competitive brief before a scheduled demo
– A positioning document was revised after a competitor repositioning signal
– A deal was won in which the rep specifically referenced a recent competitor move
The simplest activation metric is the signal-to-action conversion rate: of all signals your program generates in a month, what percentage results in a documented action? This number tells you whether your detection and distribution layers are calibrated correctly. A signal-to-action rate below 20% usually means the signals are too noisy or the recommended actions are too vague.
Metrivant addresses this at the detection layer by including one recommended action per signal, built into the signal output. The recommended action is specific to the type of competitor move detected, so the distribution step produces an actionable brief rather than a raw data point.
—
## Staffing and Resource Requirements
CI programs do not require a full-time headcount to start. The founding CI function in most B2B SaaS companies is a PMM who owns competitive as one of three or four responsibilities.
The minimum viable CI program runs on roughly 2-3 hours per week once the detection layer is automated. That time goes toward:
– Reviewing high-priority signals and deciding on actions
– Updating battlecards based on verified changes
– Distributing competitive briefs to sales before competitive deals
– Running a monthly competitive review with leadership
The hour investment scales with the number of competitors and the complexity of the market, not with the volume of CI deliverables produced. A program that produces 10 accurate, verified battlecards is more valuable than one that produces 40 battlecards built on quarterly manual audits.
—
## What to Monitor First: The Priority Competitor Stack
Not all competitors warrant the same monitoring depth. A practical starting point:
**Tier 1 (real-time monitoring, maximum coverage):** Your top 3 direct competitors. Price pages, features pages, homepage, changelog, careers page. These are the companies named in your most recent loss reports.
**Tier 2 (weekly monitoring, selective coverage):** Adjacent competitors and emerging players. Homepage, pricing page, blog. These companies are not yet named in loss reports but show up in discovery conversations.
**Tier 3 (monthly monitoring, minimal coverage):** Indirect competitors and potential entrants. Homepage only, plus any specific pages that are transition indicators (pricing tiers, feature announcements).
As your program matures, Tier 2 companies that show transition signals get promoted to Tier 1. Tier 3 companies that stay quiet for 6 months can be deprioritized. The monitoring structure is dynamic, not fixed.
—
## A Real Detection in Practice
In March 2026, a Metrivant system monitoring Mercury in the fintech sector detected a coordinated product and positioning move. The system classified it as feature_launch combined with positioning_shift, resolving to product_expansion and market_reposition in the intelligence layer. The confidence score was 0.91. The evidence chain was fully inspectable: before and after page excerpts, classification, strategic implication, and one recommended action.
A PMM team with this data updated the competitive battlecard the same day and adjusted their positioning language before their next fintech prospect call. Without a detection layer in place, that move would have surfaced weeks later, after a loss debrief, when the adjustment would have come too late.
That is what building detection-first produces. You know before the deal. Not after.
See the full detection pipeline explained in the 8-stage pipeline guide. For a comparison of CI tools across this architecture, see the best competitive intelligence tools roundup. For the evidence chain approach in depth, see the evidence chain guide.
Start building the detection layer of your CI program at metrivant.com/trial.
—
## Frequently Asked Questions
**What does a competitive intelligence program include?**
A competitive intelligence program includes four operational layers: detection (monitoring competitor pages for changes), classification (identifying what type of move a change represents), distribution (delivering intelligence to the right people at the right time), and activation (ensuring intelligence drives action). A program also typically includes deliverables like battlecards and competitive newsletters, which are outputs of the intelligence layer rather than the program itself.
**How long does it take to build a competitive intelligence program from scratch?**
A minimum viable CI program with automated detection can be operational within 1-2 weeks for a small competitor set of 5-10 companies. The detection layer setup requires defining which pages to monitor and at what cadence. Classification and distribution take an additional 2-4 weeks to configure correctly. Full activation tracking, where the program measures what actions signals produce, typically takes 60-90 days to build meaningful data.
**How many competitors should a competitive intelligence program monitor?**
Most PMM teams start with 5-10 direct competitors and expand over time. The practical limit depends on the monitoring infrastructure: manual programs become unmanageable above 5-7 competitors, while automated systems can scale to 50-150 competitors without adding headcount. Metrivant monitors up to 25 competitors on the Pro plan at $19/month.
**What is the most common reason CI programs fail?**
The most common failure mode is building deliverables before establishing a reliable detection layer. Teams produce battlecards based on quarterly manual audits, then find that by the time the battlecard is published, the competitor has already moved again. Programs that start with automated, evidence-backed detection produce deliverables that are accurate at the moment of distribution and easier to maintain.
**How does Metrivant support building a CI program from scratch?**
Metrivant handles the detection and classification layers automatically. The 8-stage pipeline captures page states, extracts content, establishes baselines, detects changes, classifies signal types, generates evidence chains with before/after excerpts and confidence scores, and produces a recommended action per signal. This gives teams a production-grade detection and classification layer from day one, without needing to build and maintain the underlying infrastructure. Plans start at $9/month at metrivant.com/pricing.
A competitive intelligence program requires four layers: detection (verified signal capture), classification (what type of move is this), distribution (getting intelligence to the right people), and activation (turning intelligence into action). Most programs fail because they skip the detection layer and build deliverables on top of unverified intelligence. Building detection first produces a program that is defensible, scalable, and actually changes deal outcomes.